


Cloudflare caused a significant outage that hit more than a dozen data centres and hundreds of websites. The services were brought down by a change that was supposed to increase network resilience.
One of the most important internet service is Cloudflare Content Delivery Network (CDN). The US company also offers various cybersecurity services, performance optimisation, and distributed denial-of-service protection for web domains.
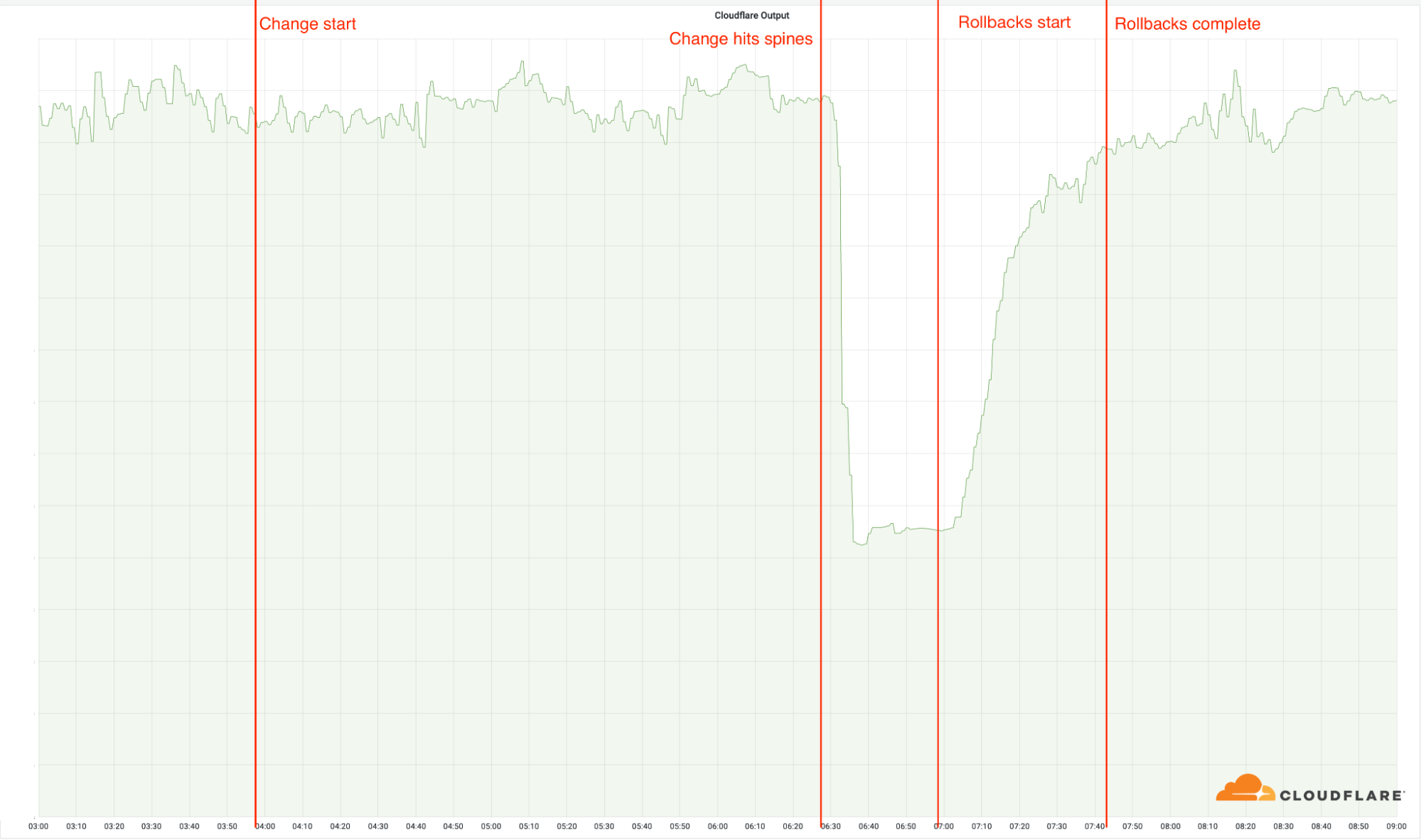
On June 21, 2022, Cloudflare reported having a problem. This affected the traffic for 19 data centres. After investigating, Cloudflare stated:
An outage at Cloudflare had an impact on traffic in 19 of our data centres. Unfortunately, these manage a large majority of our traffic. This glitch resulted from a change made as part of an ongoing project to increase reliability in our busiest sites.
The entire list of impacted websites and services is based on users’ feedback. There were several services unavailable including, but not limited to, Amazon Web Services,, Coinbase, Amazon, Twitch,Telegram, Discord, DoorDash, Gitlab, and Steam.
According to company, the event was a “critical P0,” which is generally defined as an urgent, top-priority issue.
Hit on major Cloudflare locations
At around 06:34 UTC, the firm started investigating the situation after receiving reports from users and clients all around the world that access to Cloudflare’s network was disrupted. According to the company, the event caused an HTTP 500 error and had an impact on connection over “wide areas” of Cloudflare’s network.
Cloudflare also added:
The incident has an impact on all data plane services on our network. We’re keeping an eye on the outcomes. Some websites that had been offline due to the issue in network were now back online.
At 06:27 UTC, an outage began because of a change to the network configuration in certain areas. Beginning at 06:58 UTC, the first data centre was brought back up, and by 07:42 UTC, all data centres were functional.
According to your location, you might not have been able to access websites and services that use Cloudflare. Cloudflare continues to function correctly in other places. Despite making up only 4% of Cloudflare’s worldwide network, the affected locations’ outage had a 50% global impact on the amount of HTTP requests they were able to process.
The alteration that caused today’s outage was a part of a wider effort that involved moving Cloudflare’s busiest data centres to a more secure and flexible architecture known as Multi-Colo PoP (MCP).
Ashburn, London, Frankfurt, Mumbai, Newark, Manchester, Miami, Milan, Osaka, Sao Paulo, Amsterdam, Atlanta, Los Angeles, Madrid, San Jose, and Sydney were all impacted by incident.
Cloudflare wrote in a blog post:
We have made considerable investments in its MCP architecture to increase service availability but, with this extremely distressing occurrence, we have failed to live up to the expectations of our customers. We apologize for the trouble to our clients and to everyone else who couldn’t use Internet resources during the outage.
Incidents like this sometimes lead to malicious actors seeing an opportunity to send malicious emails apologising or explaining an incident, so you should remain even more vigilent after such a global event.
To help you and your colleagues with this vigilience consider start your Phishing Tackle two-week free trial today.





