


Meta Platforms will not introduce its Meta Artificial Intelligence models in Europe at this time after being instructed to postpone its plans by the Irish privacy regulator. According to the American social media company a week ago, the decision was made in response to concerns over the usage of user data from Facebook and Instagram.
The Irish Data Protection Commission (DPC), the primary EU regulator for a number of EU data protection agencies, has opposed Meta. Additionally, the Information Commissioner’s Office (ICO) of the United Kingdom requested Meta to put its plans on hold until it resolved their concerns.
The activist organisation NOYB (None of Your Business) prompted data protection authorities in Austria, Belgium, France, Germany, Greece, Italy, Ireland, the Netherlands, Norway, Poland, and Spain to act, which resulted in this response.
The main problem is that, despite Meta’s claims that it would only utilise material that was licenced and publicly available, the business intends to use personal data to train its AI models without asking users’ permission.
According to DPC statement:
The DPC welcomes the decision by Meta to pause its plans to train its large language model using public content shared by adults on Facebook and Instagram across the EU/EEA. This decision followed intensive engagement between the DPC and Meta. The DPC, in cooperation with its fellow EU data protection authorities, will continue to engage with Meta on this issue.
Navigating GDPR Challenges: Meta’s AI Training Shift Sparks Controversy
In the US, Meta already trains its AI on user-generated material. However, Meta and other companies trying to improve their AI systems face difficulties due to Europe’s strict General Data Protection Regulation (GDPR) laws. Large language models (LLM) are among the systems that depend on user-generated training materials.
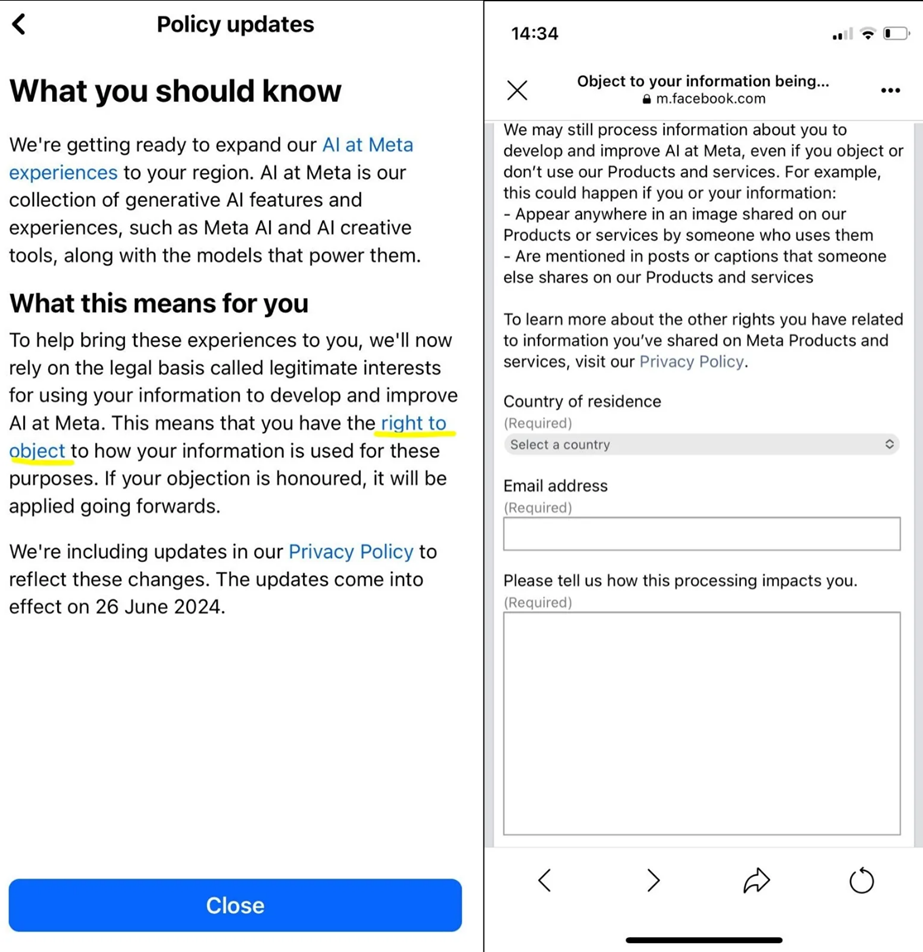
Meta notified users of a modification to its privacy policy last month. With this modification, Meta will be able to train AI using publicly accessible Facebook and Instagram content.
Meta reported that it notified more than 2 billion people about the upcoming modifications. But these notifications were mixed in with ordinary alerts like friends’ birthdays, photo tags, and group announcements, unlike important public posts like voting urges that show up at the top of users’ feeds.
Because of this, people who don’t often check their alerts may easily miss notifications. It is possible that some people did not even know they could object or opt out when they received the message. Without mentioning that customers had an option, the message only asked them to click through to find out how Meta will utilise their information.
This includes comments, connections with companies, status updates, photographs, and captions. According to Meta, the change is needed to represent “the diverse languages, geography, and cultural references of the people in Europe.”
According to Stefano Fratta, Global Engagement Director of Meta Privacy Policy:
We remain highly confident that our approach complies with European laws and regulations. AI training is not unique to our services, and we’re more transparent than many of our industry counterparts.
The privacy activist organisation NOYB opposed the modifications, which were set to take effect on June 26, claiming Meta’s strategy breached GDPR and filing 11 complaints with member states.
Authorities expressed concern over the time-consuming and poorly communicated opt-out process. Important notifications were hidden among standard messages, making them easy to miss. Users had to fill out an objection form instead of having a simple opt-out option.
In response to Meta, Max Schrems, the founder of noyb, said:
Meta is basically saying that it can use ‘any data from any source for any purpose and make it available to anyone in the world,’ as long as it’s done via ‘AI technology. This is clearly the opposite of GDPR compliance. Meta doesn’t say what it will use the data for, so it could either be a simple chatbot, extremely aggressive personalized advertising, or even a killer drone. Meta also says that user data can be made available to any ‘third-party’ – which means anyone in the world.
According to Meta, it wasn’t the first company to train AI using customer data from Europe. The social media platform claimed that it was taking OpenAI and Google’s lead. Meta is a component of the AI arms race, exposing the vast amount of personal data that Big Tech has on each and every one of us.
Reddit said earlier this year that it hopes to licence its data to businesses like OpenAI and Google for over $200 million in revenue over the next several years. But Google has previously paid huge penalties for training its AI algorithms using copyrighted journalistic content.
Phishing Tackle provides training course videos that cover different types of artificial intelligence threats designed to counter the ever-changing risks posed by artificial intelligence. We offer a free 14-day trial to help train your users to help train your users in avoiding these types of attacks and to test their knowledge with simulated phishing attacks.





